
Abstract
While spatial autocorrelation is used in spatial sampling survey to improve the precision of the feature’s estimate of a certain population at area units, spatial heterogeneity as the stratification frame in survey also often have a considerable effect upon the precision. Under the context of increasingly enriched spatiotemporal data, this paper suggests an information-fusion method to identify pattern of spatial heterogeneity, which can be used as an informative stratification for improving the estimation accuracy. Data mining is major analysis components in our method: multivariate statistics, association analysis, decision tree and rough set are used in data filter, identification of contributing factors, and examination of relationship; classification and clustering are used to identify pattern of spatial heterogeneity using the auxiliary variables relevant to the goal and thus to stratify the samples. These methods are illustrated and examined in the case study of the cultivable land survey in Shandong Province in China. Different from many stratification schemes which just uses the goal variable to stratify which is too simplified, information from multiple sources can be fused to identify pattern of spatial heterogeneity, thus stratifying samples at geographical units as an informative polygon map, and thereby to increase the precision of estimates in sampling survey, as demonstrated in our case research.












Similar content being viewed by others


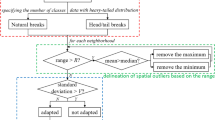
References
Agrawal R, Imielinski T, Swami A (1993) Mining association rules between sets of items in large databases. In: Proceedings of the ACM SIGMOD conference on management of data, WA, USA
Alexander H, Daniel AK (1998) An efficient approach to clustering in large multimedia databases with noise. In: Proceedings of the 4th international conference on knowledge discovery and data mining, AAAI Press
Aleksander Ø (1999) Discernibility and rough sets in medicine: tools and applications (Dissertation). Norwegian University of Science and Technology, Norway
Anselin L (1992) Spacestat: a program for statistical analysis of spatial data, NCGIA, Santa Barbara
Bonham-Carter FG (1994) Geographic information systems for geoscientists: modelling with GIS. Pergamon, Ottawa
Bergen KM, Brown DG, Rutherford JF, Gustafson EJ (2005) Change detection with heterogeneous data using ecoregional stratification, statistical summaries and a land allocation algorithm. Remote Sens Environ 97:434–446
Cochran WG (1977) Sampling techniques. Wiley, New York
Cressie N (1991) Statistics for spatial data. Wiley, New York
Ertoz L, Steinbach M, Kumar V (2003) Finding clusters of different sizes, shapes, and densities in noisy, high dimensional data. In: Proceedings of third SIAM international conference on data mining, San Francisco, CA, USA
ESRI (2004) ArcGIS desktop help. ESRI, Redlands
Gallego FJ (2005) Stratified sampling of satellite images with a systematic grid of points. ISPRS J Photogramm Remote Sens 59:369–376
Gediga G, Duntsch I (2000) Statistical techniques for rough set data analysis. In: Polkowski L, Tsumoto S, Lin T (eds) Rough set methods and applications. Physica Verlag, Heidelberg, pp 545–565
Giarratano J, Riley G (1998) Expert systems: principles and programming. PWS Publishing Company, Boston
Goovaerts P, Jacquez GM, Marcus WA (2005) Geostatistical and local cluster analysis of high resolution hyperspectral imagery for detection of anomalies. Remote Sens Environ 95:351–367
Haining R (2003) Spatial data analysis: theory and practice. Cambridge University Press, Cambridge
Komorowski J, Pawlak Z, Polkowski L, Skowron A (1999) Rough sets: a tutorial. In: Rough fuzzy hybridization. Springer, Heidelberg
Kong W, Ou M (2006) Research on the change of the cultivated land’s areas and its driving factors of Shandong Province, (in Chinese). Agric Econ 28:74–76
Lawrence R, Wright A (2001) Rule-based classification systems using classification and regression tree (CART) analysis. Photogramm Eng Remote Sens 67:1137–1142
Lawrence R, Bunn A, Powell S, Zambon M (2004) Classification of remotely sensed imagery using stochastic gradient boosting as a refinement of classification tree analysis. Remote Sens Environ 90:331–336
Li D, Wang S, Li D, Wang X (2002) Theories and technologies of spatial data mining and knowledge discovery (in Chinese). Geomat Inf Sci Wuhan Univ 27(3):221–233
Li L, Wang J, Liu J (2005) Optimal decision-making model of spatial sampling for survey of China’s land with remotely sensed data. Sci China Ser D 48(6):752–764
Liu J, Zheng X (2004) Correlate analysis between the dynamic changes of cultivated lands and grain total yield (in Chinese). Areal Res Dev 12(6):102–105
Liu M, Zhuang D, Hu W (2001) On current cultivated land change based on geomorphology and spatial differentiation characteristics (in Chinese). Resour Sci 23(5):11–16
McRoberts RE, Holden GR, Nelson MD, Liknes GC, Gormanson DD (2006) Using satellite imagery as ancillary data for increasing the precision of estimates for the Forest Inventory and Analysis program of USDA Forest Service. Can J For Res 36:2968–2980
Michalski R, Bratko I, Kubat M (1998) Machine learning and data mining: methods and applications. Wiley, London
Miller HJ, Han J (2001) Geographic data mining and knowledge discovery. Taylor & Francis, New York
Mitchell TM (1997) Machine learning. McGraw-Hill, New York
Mjolsness E, DeCoste D (2001) Machine learning for science: state of the art and future prospects. Science 293(5537):2051–2055
Pal SK, Ghosh A, Shankar BU (2000) Segmentation of remotely sensed images with fuzzy thresholding and quantitative evaluation. Int J Remote Sens 21(11):2269–2300
Rijsbergen CV (1979) Information retrieval, 2nd edn. Butterworths, London
Ripley BD (1981) Spatial Statistics. John Wiley & Sons, New York
Rodriguez-Iturbe I, Mejia JM (1974) The design of rainfall networks in time and space. Water Resour Res 10:713–728
Steinbach M, Klooster S, Potter C (2003) Discovery of climate indices using clustering, KDD 2003 Washington, DC, http://www-users.cs.umn.edu/∼kumar/papers/kdd03_nasa.pdf
Tan PN, Steinbach M, Vipin K (2006) Introduction to data mining. Pearson Education, Inc., New York
Tobler W (1979) In: Gale, Olsson (eds) Cellular geography, philosophy in geography. Reidel, Dordrecht
Wang G (2001) Theory and knowledge acquirement of rough set (in Chinese). Press of Xian Transportation University, Xian
Wang J, Liu J, Zhuang D, Li L, Ge Y (2002) Spatial sampling design for monitoring the area of cultivated land. Int J Remote Sens 23(2):263–284
Witten IH, Frank E (2000) Data mining, practical machine learning tools and techniques with JAVA implementations, Elsevier, Singapore
Zhang Y, Hang Y, Chen H, Xue F, Wang J, Sun G (2001) The impact of dimensions of sampling geographic cells of statistical indicators on the distribution of disease. Literature and Information of Preventative Medicine (in Chinese), 7(6):613–615
Zhang P, Steinbach M, Kumar V, Shekhar S, Tan PN, Klooster S, Pot C (2005) Discovery of patterns in earth science data using data mining. In: New generation of data mining applications, vol 4. Wiley, New York
Zeng Z (2004) Research on computer classification of satellite images and application in geoscience (in Chinese). Science Press, Beijing
Acknowledgments
This research has been done in support of the grants 40601077/D0120 and 40471111/D0120 from the Natural Science Foundation of China, and the grant 2007AA12Z233 from Hi-tech Research and Development Program of China (863).
Author information
Authors and Affiliations
Corresponding author
Appendices
Appendix 1: The equation of k-nearest neighbor for a nominal variable
where \( \hat{f}(x_{i} ) \) is the estimate of the grid unit x i , V is the finite set {v 1,…,v s } of the band variable, k is the number of the nearest neighbors, f(s i |s i ∈ N(x i )) is the categorical or discrete value of the ith nearest neighbor unit, s i belonging to the neighborhood of x i , N(x i ), δ(a,b) = 1 if a = b and δ(a,b) = 0 otherwise.
Appendix 2: A brief introduction to rough set
The rough set assumes that an information system consists of the 4-tuples S = 〈U, B, V, f〉 where U is a finite set of objects, i.e. each a gird unit, x i, in our dataset, B is a finite set of attributes, i.e. each a band in the dataset, \( V = {\bigcup\limits_{b \in B} {V_{b} } }, \) V b is the value domain of the band attribute, b and f: U × B → V is a total function such that f(x i , b) ∈ V b for every b ∈ B, x i ∈ U, called information function. Any pair (b,v), b ∈ B, v ∈ V q is called descriptor in S. In rough set, those attributes used in classification are called the conditional variables, in fact, auxiliary variables X k (k is the order no. of band variables) and the classification variable is the decisive variable, Y. Conditional variables are used to classify the object x i in the system. If two objects in the dataset U, x i and x j have the relation, f(x i ,b) = f(x j ,b) for every b ∈ B, we call x i and x j indiscernible and all of such indiscernible objects composes a class set of the goal variable. Each conditional (auxiliary) variable has different levels of classifying the objects and the level is called significance of attribute (SA) in terms of the decisive variable. For more, please refer to Aleksander (1999), Komorowski et al. (1999) and Wang (2001).
Appendix 3: Modeling for the stratification survey of the cultivatable land’s areal proportion
Given
- N :
-
is the number of all the aerial photos that cover the whole study region;
- n :
-
is the number of the photo units sampled;
- L :
-
is the number of stratums;
- N h :
-
is the total number of units in the hth stratum;
- n h :
-
is the number of units sampled for analysis in the hth stratum;
- β ih :
-
is the areal proportion of the cultivable land of the ith aerial photo in the hth stratum;
-
1.
If a sample unit of aerial photo is overlapped by several polygons within different strata the samples will be separated into smaller sub-sample units within the strata. The areal proportion of the cultivatable land in the sub-sample unit remains same and each sample unit’s weight in the stratum is proportional to the unit’s total area: w ih = S ih /S h where S ih is the area of the sample unit in the hth stratum and S h is the total area of all the units sampled in the hth stratum.
-
2.
Within each stratum, the units are randomly sampled according to the principle of SRS. However, the estimation equation with spatial proportion sampling is derived from Ripley (1981) and Wang et al. (2002).
The sampling proportion:
$$ f_{h} = n_{h} /N_{h} ; $$(6)The number of units sampled:
$$ a = f_{h} N_{h} ; $$(7)The proportion:
$$ \hat{\beta }_{h} (a) = {\sum\limits_{i = 1}^{n_{h} } {\beta _{{ih}} w_{{ih}} } } $$(8)The variance
$$ \begin{aligned}{} \hat{\sigma }_{{\hat{\beta }_{h} (a)}} (n_{h} )^{2} & = E_{h} {\left[ {\hat{\beta }_{h} (a) - \beta _{h} (a)} \right]}^{2} = E{\left[ {\frac{1} {{n_{h} }}{\sum\limits_{a = 1}^{n_{h} } {n_{h} } }\beta _{h} (a)w_{h} (a) - \frac{1} {{N_{h} }}{\int\limits_{N_{h} } {(n_{h} \beta _{h} (a)w_{h} (a)\;{\text{d}}a} }} \right]}^{2} \\ {\text{ }} & = \frac{1} {{n_{h} }}\{ 1 - E_{h} [r(a - {a}\ifmmode{'}\else$'$\fi)]\} \hat{\sigma }^{2}_{{\hat{\beta }_{h} (N_{h} )}} = F(n_{h} )\hat{\sigma }^{2}_{{\hat{\beta }_{h} (N_{h} )}} \\ \end{aligned} $$(9)where β h (a) = β ah , w h (a) = w ah , and \( F(n_{h} ) = (1/n_{h} )\{ 1 - E_{p} [r(a - {a}\ifmmode{'}\else$'$\fi)\left| R \right.]\} ;\,E_{h} [r(a - {a}\ifmmode{'}\else$'$\fi)\left| R \right.] \) is the expected value of the spatial correlation structure of the target variable in the study region, R (Rodriguez-Iturbe and Mejia 1974; Ripley 1981):
$$ \hat{\sigma }_{{\hat{\beta }_{h} (a)}} (N_{h} ) \equiv {\sum\limits_{a = 1}^{N_{h} } {{\left\{ {{\left[ {\beta _{h} (a)w_{h} (a) - {\sum\limits_{a = 1}^{N_{h} } {\beta _{h} (a)w_{h} (a)} }} \right]}^{2} w_{h} (a)} \right\}}} } $$(10) -
3.
For the estimation of the population’s mean, Cochran’s equation is mainly referred to. The estimate of \( \ifmmode\expandafter\bar\else\expandafter\=\fi{\beta }_{{{\text{STR}}}} \) is
$$ \hat{\ifmmode\expandafter\bar\else\expandafter\=\fi{\beta }}_{{{\text{STR}}}} = \frac{{{\sum\limits_h^L {n_{h} \hat{\ifmmode\expandafter\bar\else\expandafter\=\fi{\beta }}_{h} } }}} {n} = {\sum\limits_{h = 1}^L {w_{h} \hat{\ifmmode\expandafter\bar\else\expandafter\=\fi{\beta }}_{h} } }\quad {\text{where}}\;n = n_{1} + n_{2} + \cdots + n_{L} $$(11)The sampling proportion in each stratum:
$$ f_{h} = \frac{{n_{h} }} {n} = f = \frac{{{\sum\nolimits_{h = 1}^{n_{L} } {n_{h} } }}} {N} $$(12)The variance:
$$ \hat{V}(\hat{\ifmmode\expandafter\bar\else\expandafter\=\fi{\beta }}) = {\sum\limits_{h = 1}^L {w^{2}_{h} \hat{V}_{h} (\hat{\ifmmode\expandafter\bar\else\expandafter\=\fi{\beta }})} } $$(13)where \( \hat{V}_{h} (\hat{\ifmmode\expandafter\bar\else\expandafter\=\fi{\beta }}) \) is the variance of the stratum h.
Rights and permissions
About this article
Cite this article
Li, L., Wang, J., Cao, Z. et al. An information-fusion method to identify pattern of spatial heterogeneity for improving the accuracy of estimation. Stoch Environ Res Risk Assess 22, 689–704 (2008). https://doi.org/10.1007/s00477-007-0179-1
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00477-007-0179-1